In our previous blog post, we announced TIBCO Spotfire’s Amazon Redshift Ready certification. With the release of Spotfire 11, we’re now able to share all of the details around certification and completely overhauled integration and what this means for co-customers.
Headlining the enhancements of the Amazon Redshift Ready certification in Spotfire 11 is self-service support for Amazon Redshift Spectrum, offering an inroad to analytics on top of files in Amazon S3. Gone are the days when these were accessed via custom queries, now simply adding to the visual data exploration experience with just a few clicks. Additionally, you get the complete power of Amazon Redshift directly on your S3 data thanks to the certified Spotfire integration.
Starting with authentication options, there are also several new features for which the Spotfire team received significant user feedback from organizations requiring usage of the latest authentication methods. Traditional on-premises authentication options are migrated into more modern options based on Identity providers. With Spotfire 11 you are now able to connect using:
- AWS profile
- AWS IAM Credentials
- AD FS
- Azure AD
- Okta
- PingFederate
- Username and Password
With authentication as a central piece of connecting to your data, Amazon provides a wide range of alternatives. Some are available directly in the user interface but new in Spotfire 11 is the ability to use any options virtually by defining them as key value pairs. This simplifies the tuning and tweaking of an organization’s connectivity for optimal performance and meeting demands of how clients connect to Redshift.
With complex, specific, and unique business needs, Spotfire and Amazon Redshift users can opt to use their own preferred alternative for selecting the data they need. As users are enabled to browse Spectrum tables without writing any SQL, that’s already available in Spotfire and your data views may be prepared just as before by:
- Reusing joins
- Defining your own joins
- Renaming columns
- Defining primary key columns
- Defining prompts to limit data in each session
- Adding optional custom queries
- …and so on
This is all part of reusable and shareable Spotfire data connections.
Exploring data ad hoc in Spotfire
Users are now able to mark more data points than ever before. Tuples in queries allow for adding more tuples into ‘WHERE’ clauses. Selecting several values at once without the dreaded message that too many are selected to perform marking is a huge usability and performance gain.
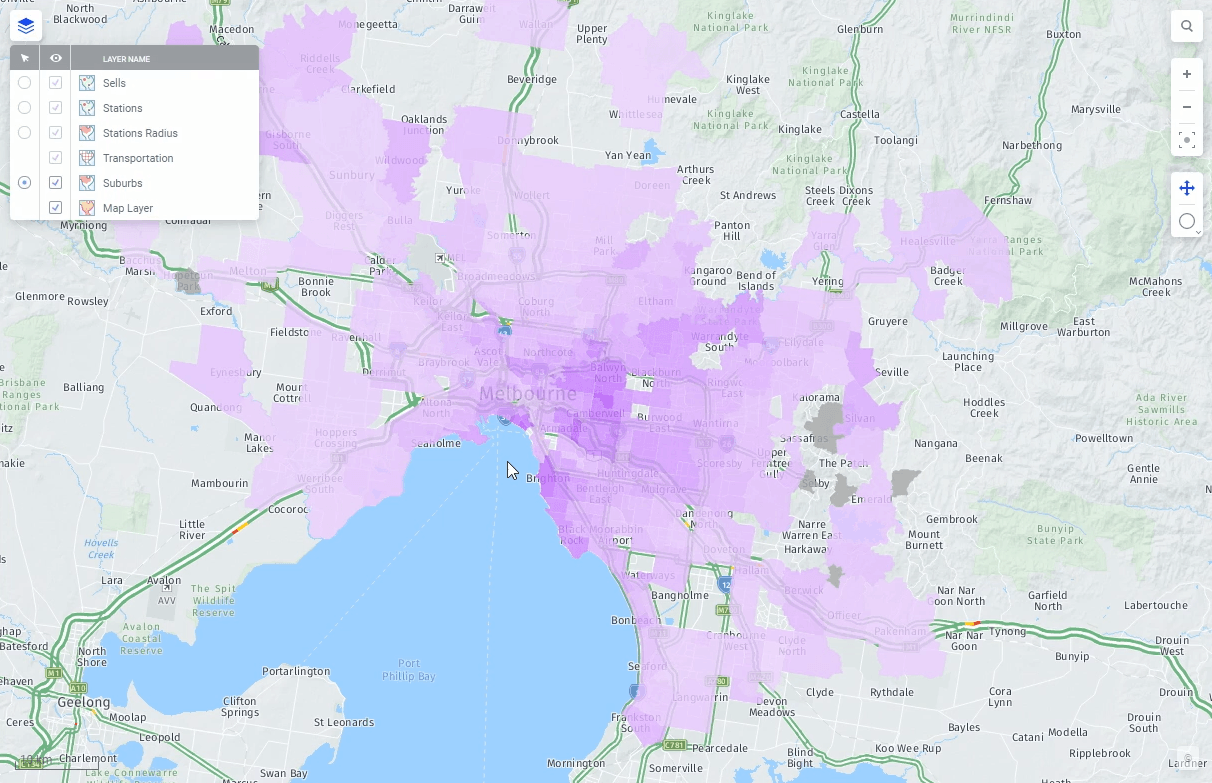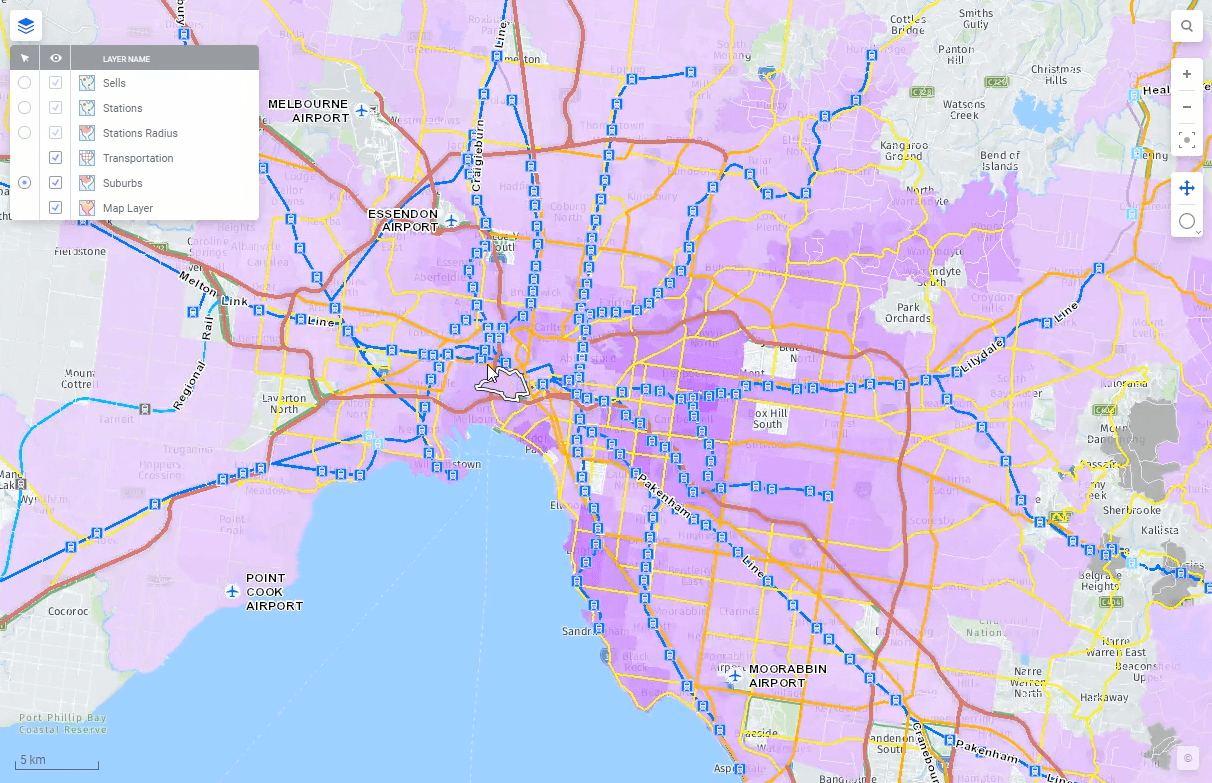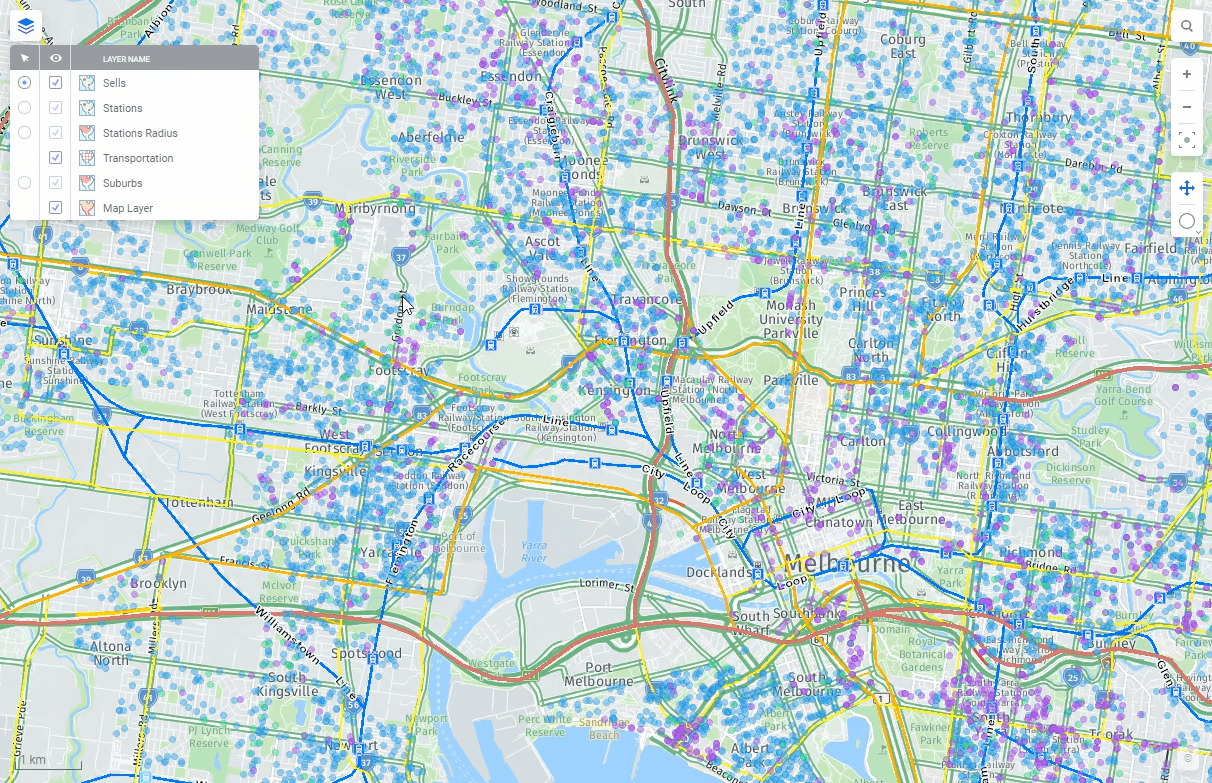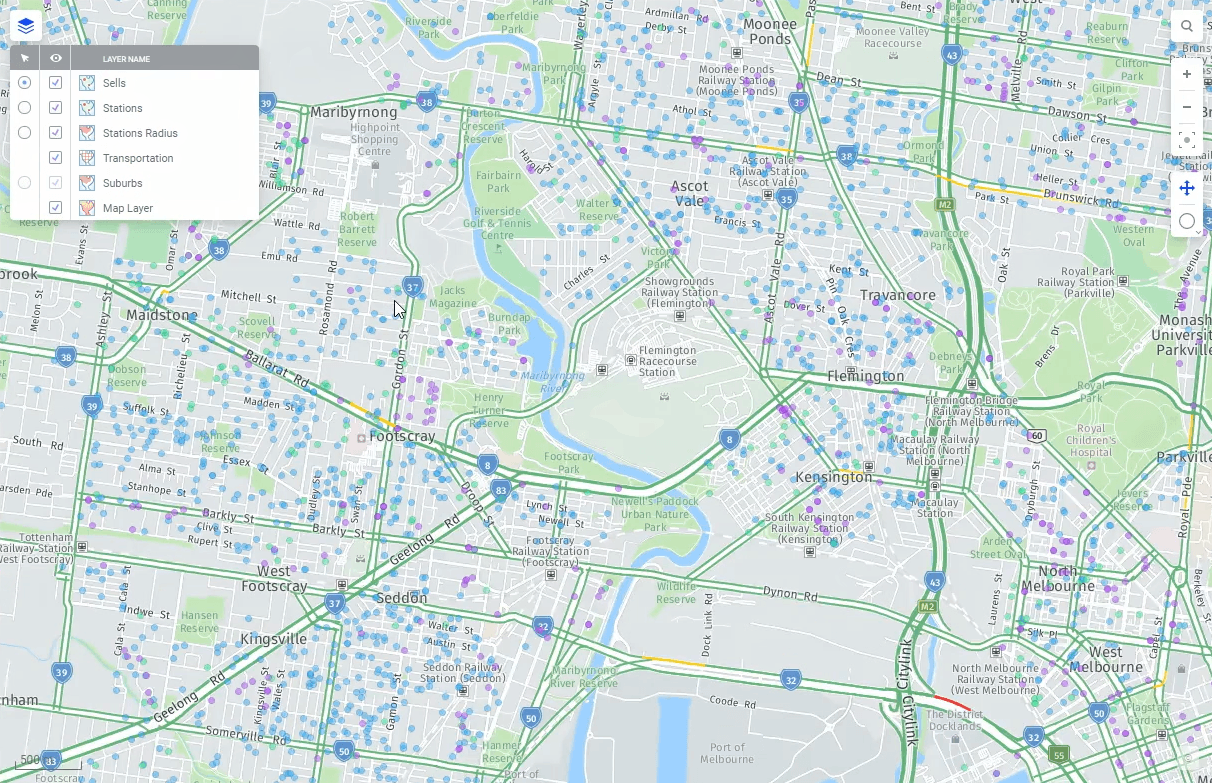
With geoanalytics as a Spotfire strong suit, Spotfire 11 also now provides out-of-the-box support for importing and visualizing geographical data in Amazon Redshift. Automatic brush linking between visualizations and the ability to mark data more freely you would probably like to do some advanced calculations in visualizations or as reusable calculated columns. With Spotfire 11 you have a huge library of math, statistical, text and other functions available. The possibilities of Amazon Redshift and Spotfire present limitless new opportunities to explore.
According to Sercan Icli, Data Visualization and Advanced Analytics Platform Engineering Lead at MSD Czech Republic:
“Amazon Redshift is a mission-critical platform at MSD, especially within the MSD Research Laboratories and MSD Manufacturing Divisions, where our analysts and data scientists rely on self-service Amazon Redshift access from TIBCO Spotfire. At MSD, we are excited to see the close cooperation between Amazon and TIBCO on the new features brought to Spotfire 11. Point-and-click support for Amazon Redshift Spectrum will save time and allow data from S3 buckets to be consumed easily from TIBCO Spotfire. It is also essential for us to follow all the MSD security policies and use authentication methods like PingFederate.”
For more, check out our on-demand webinar on the latest data access and connectivity updates.